Recently, I setup SRM 6.0 with MirrorView storage based replication. It was quite the adventure. The environment was using SRM 5.0 and MirrorView, and we upgraded them to vSphere 6.0 and SRM 6.0 recently. I wanted to get my findings down in case it may help others setting this up. I found when I ran into issues, it wasn’t easy finding people who were doing this, as many who are using VNXs are using RecoverPoint now instead of MirrorView.
Version Support
First off, you might be wondering why I recently deployed SRM 6.0 instead of 6.1. That’s an easy question to answer – currently, there is no support for MirrorView with SRM 6.1. I’m posting this article in 11/2015, so that may change. Until it does, you’ll need to go with SRM 6.0 if you want to use MirrorView.
Installation of Storage Replication Adapter
I’m assuming you already have installed SRM, and configured the pairings and what not. At the very least, have SRM installed in both sites before you proceed.
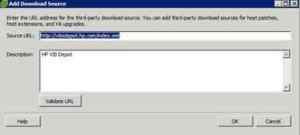
Here’s where things got a little goofy. First off, downloading the SRA is confusing. If you go to VMware’s site to download SRA’s, you’ll see two listings for the SRA, with different names, suggesting they work for different arrays, or do something different, or are different components.

They’re actually so far as I can tell two slightly different versions of the SRA. Why are they both on the site for download? No idea. So I went with the newer of the two.
You also need to download and install Navisphere CLI from EMC for the SRA to work. There are a few gotchas on the install of this to be aware of. Install this first.
During installation, you need to ensure you check the box “Include Navisphere CLI in the system environment path.”

That’s listed in the release notes of the SRA, so that was easy to know. You also need to select to not store credentials in a security file.
I ended up having issues with the SRA being able to authenticate to the arrays when I originally told it to store credentials thinking this could allow easier manual use of Navisphere CLI should the need arise, but that messed things up, so uninstalled, and reinstalled Navisphere CLI without that option, and the bad authentication messages went away.
Next, install the SRA, which is straight forward. After the installation of the SRA, you must reboot the SRM servers, or they will not detect that they have SRA’s installed. That takes care of the SRAs.
Configuring the SRAs
Once you have installed the SRA’s, it’s time to configure the array pairs. First, go into Site Recovery within the vSphere Web Client, and click Array Based Replication.

Next, click Add Array Manager.

Assuming you’re adding arrays from two sites, click “Add a pair of array managers”.

Select the SRM Site location pair for the two arrays.

Select the SRA type of EMC VNX SRA.

Enter the Display name, the management IPs of the array, filters for the mirrors or consistency groups if you are using MirrorView for multiple applications, and the username and password info for the array for each site. Be sure to enter the correct array info for the indicated site.

I always create a dedicated SRM service account within the array, so it’s easy to audit when SRM initiates actions on the storage array.
You’ll need to fill the information out for each site’s array.
Keep the array pair checked and click next.

Review the summary of action and click finish.
At this point, you can check the array in each site and see if it is aware of your mirrors being replicated.

So far so good! At this point, you should be able to create your protection groups and recovery plans, and start performing tests of a test VM and recoveries as well.
Problems
I began testing a test Consistency Group within MirrorView, which contained one LUN, which stored a test VM. Test mode worked immediately to DR. Failover to the DR site failed, as it often does in my experience with most Storage Based Replication deployments. No problem, I simply launch it again, and it works, and it did in this case.
With the VM then in the DR site, I performed an isolated test back to production, which worked flawlessly. It’s when I tried to fail back to production I encountered a serious problem. SRM reported that the LUN could not be promoted. Within SRM, I was given only the option to try failover again. The icon was grayed out to do cleanup or a test. Relaunching failover resulted in the same result. I tried rebooting both SRM servers, vCenter, running rediscovery of the SRAs, you name it. I was stuck.
I decided to just manually clean up everything myself. I promoted the mirror in the production site, had hosts in both sites rescan for storage. The LUN became unavailable in the DR site, but in production, while the LUN was visible in terms of seeing an available LUN, the datastore wouldn’t mount. Rebooting the ESXi server didn’t help. I finally added it as a datastore, selecting not to resignature the datastore. The datastore mounted, but I found that the datastore wouldn’t mount after a host reboot. Furthermore, SRM was reporting the MirrorView consistency group was stuck failing over, showing Failover in Progress. I tried recreating the SRM protection group, re-adding the array pairs, and more, but nothing worked.
After messing with it for awhile, checking MirrorView and the VNX, VMware, etc., I gave up and contacted EMC support, who promptly had me call VMware support, who referred me back to EMC again because it was clearly an SRA problem for EMC.
With EMC’s help, I was able to cleanup the mess SRM/SRA made.
- The Failover in Progress reported by the SRA was due to description fields on the MirrorView description view. Clearing those and rescanning the SRAs fixed that problem.
- The test LUN not mounting was due to me not selecting to resignature the VMFS datastore when I added it back in.
At this point, we were back to square one, and I went through the gambit of tests. I got errors because the SRM placeholders were reporting as invalid. Going to the Protection Group within SRM and issuing the command to recreate the SRM placeholders fixed this issue.
We repeated testing again. This time, everything worked, even failback. Why did it fail before? Even EMC support had no answer. I suspect it’s because anytime I make the first attempt in a direction in an SRM environment to failover, it always fails. Unfortunately, it was very difficult to fix this time.